Databases with V
479 subscribers
About Databases with V
I mostly post stuff about databases. AMA - https://forms.gle/YHKpTBvVooNmtJQcA Mirror of my twitter account https://twitter.com/iavins
Similar Channels













Swipe to see more
Posts
James Cowling: I designed Dropbox's storage system and modeled its durability. Durability numbers (11 9's etc) are meaningless because competent providers don't lose data because of disk failures, they lose data because of bugs and operator error. Yes S3 has lost data. No it wasn't because some disks failed. If you're building your own infrastructure you should heavily invest in release process and validation testing (link in reply). You're not going to do a better job than a major cloud provider though. The best thing you can do for your own durability is to choose a competent provider and then ensure you don't accidentally delete or corrupt own data on it: 1. Ideally never mutate an object in S3, add a new version instead. 2. Never live-delete any data. Mark it for deletion and then use a lifecycle policy to clean it up after a week. This way you have time to react to a bug in your own stack. https://dropbox.tech/infrastructure/pocket-watch
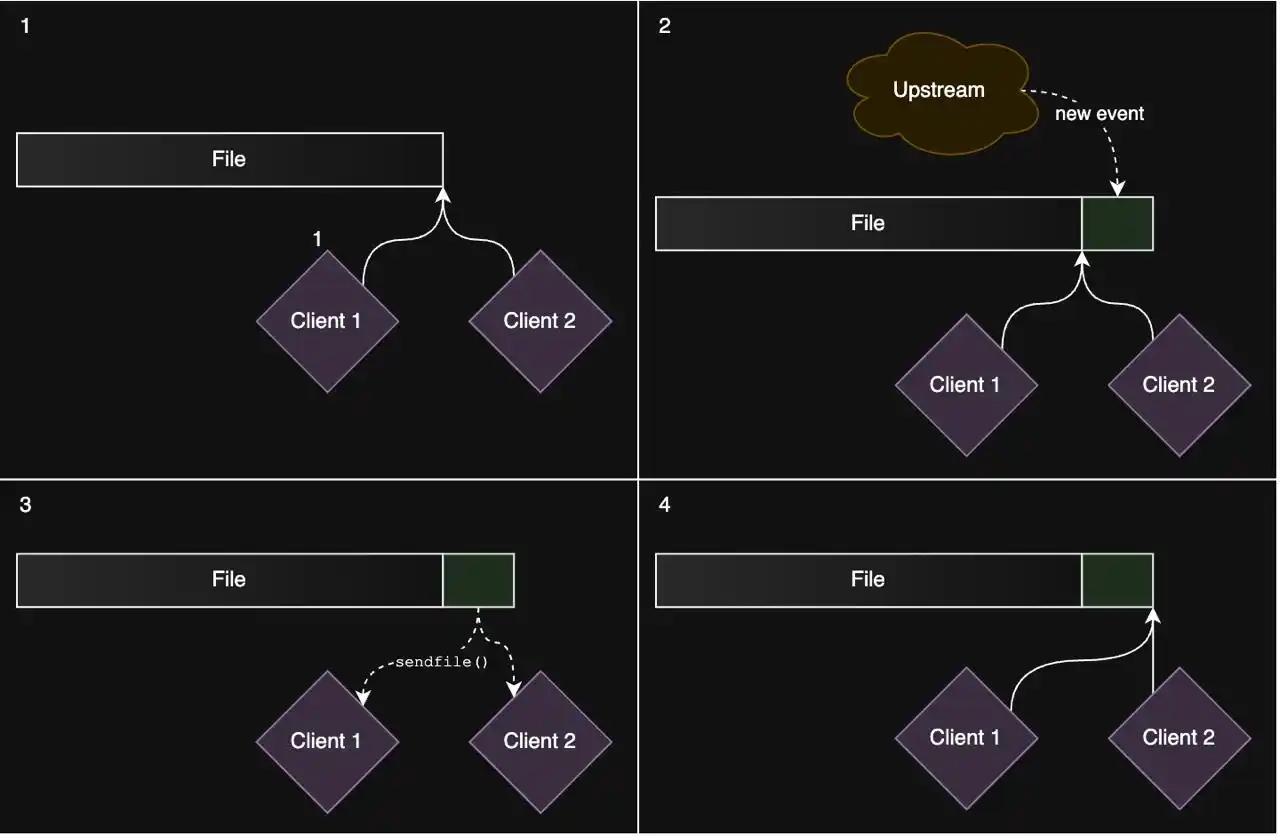
This is a great post. TLDR: - sendfile() - io_uring - FALLOC_FL_PUNCH_HOLE (we also use the last two at Turso server for the same reasons) Let the kernel do the work! Tricks for implementing a pub/sub server - https://www.asayers.com/jetrelay/
At Turso, people are creating databases at an insane pace. Over the past few months, with the rise of agentic workflows, we've seen a massive surge. Companies are creating millions of databases because it’s economically viable on Turso. Recently, I worked on scaling our proxy layer to handle a billion databases. This is the service responsible for converting a user friendly URL like `my-database-apple.turso.io` into the address of a node within our infrastructure. The proxy layer gives us the flexibility to move databases between nodes at will, while users continue using the same URL seamlessly. As the number of databases grows daily, the metadata required to maintain this mapping has been increasing significantly: around 500MB per week. That's a lot, especially considering we run multiple instances of the proxy in several regions. Worse, as memory requirements grow, we’re forced to upgrade to higher-CPU machines even if we don't actually need the extra compute power, just to get more RAM. We managed to cut down the memory usage significantly using techniques like: - Interning strings - Trimming unnecessary suffixes - LRU Cache (instead of hashmap) - Hybrid cache (in-memory + disk) Here is the full post - https://turso.tech/blog/we-rewrote-large-parts-of-our-api-in-go