Prof. Grimaldo Oliveira
June 11, 2025 at 10:12 AM
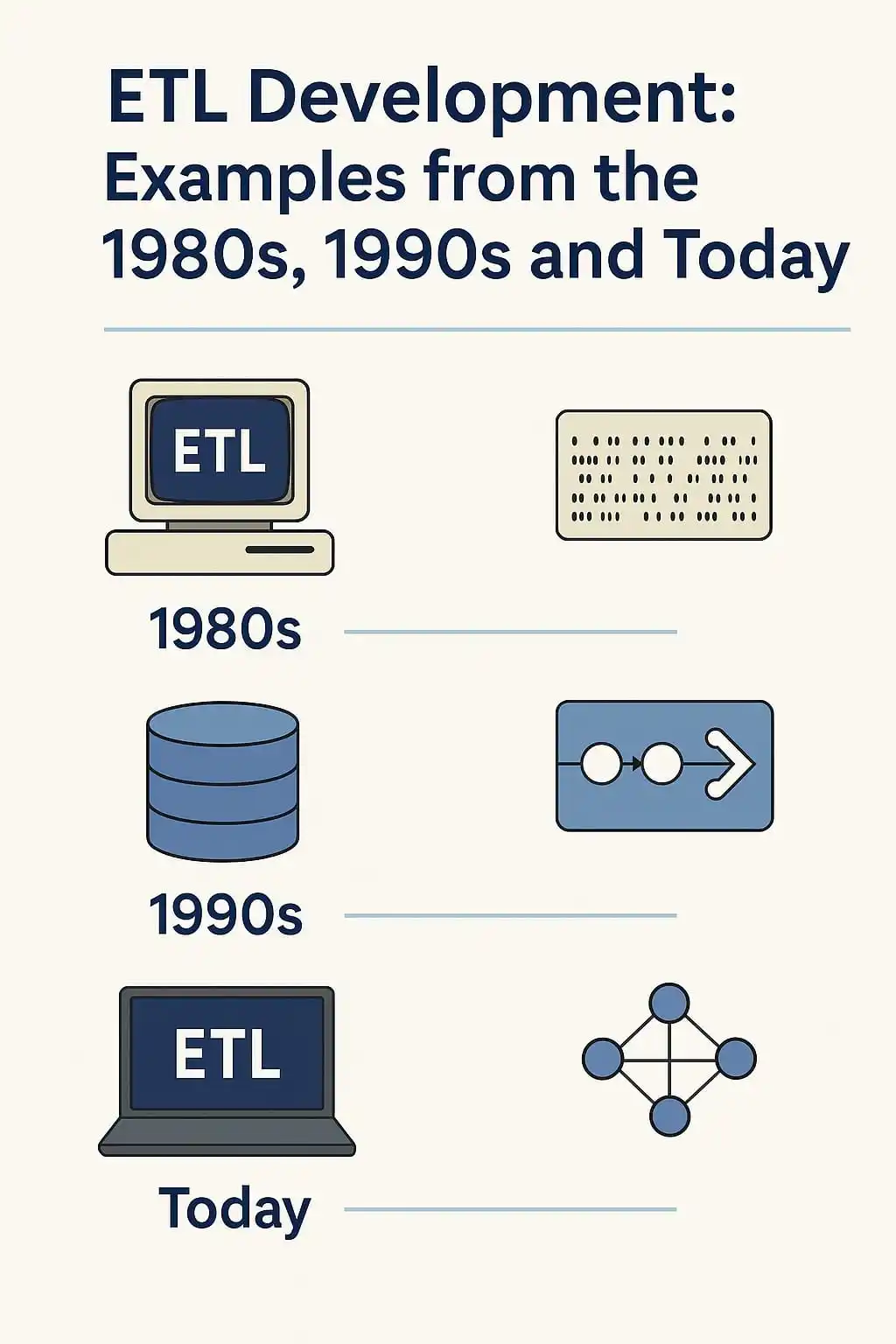
Nos anos 80, construir um processo de ETL (Extração, Transformação e Carga) era praticamente um trabalho artesanal. Os dados vinham de mainframes, arquivos em fita ou sistemas isolados. Tudo era feito com scripts escritos em linguagens como COBOL, e o tempo de resposta era contado em horas ou dias. Integrar fontes diferentes exigia um nível de esforço que hoje pareceria inimaginável.
Na década de 90, com o avanço dos bancos relacionais e ferramentas como Informatica e DataStage, surgiu um pouco mais de padronização. Ainda assim, os processos eram centralizados, lentos, e dependiam fortemente da equipe técnica. O conceito de Data Warehouse começou a ganhar força, mas a flexibilidade ainda era limitada.
Hoje, a construção de pipelines evoluiu para algo distribuído, em tempo real e com múltiplas ferramentas de código aberto, cloud e low-code. Plataformas como Apache Beam, dbt e serviços gerenciados em nuvem permitiram que engenheiros de dados construam fluxos escaláveis, modulares e auditáveis com muito mais rapidez. O dado deixou de ser um produto técnico e passou a ser parte do negócio.
E o próximo passo está se consolidando agora com o uso de IA. Modelos generativos e ferramentas de inteligência artificial já auxiliam na automação de pipelines, na identificação de anomalias, na classificação de dados e até na documentação técnica. Um assistente de IA pode gerar código, sugerir validações e até traduzir regras de negócio em queries com mais clareza do que muitos documentos.
Entender como os processos de ETL evoluíram é importante para reconhecer o que a IA pode (e deve) fazer: não substituir o profissional de dados, mas dar mais velocidade, contexto e qualidade para que ele se concentre na lógica e na entrega de valor. A história mostra que quem domina as mudanças de paradigma não só se adapta melhor, como passa a definir o futuro dos dados.