Appdate
June 8, 2025 at 08:18 AM
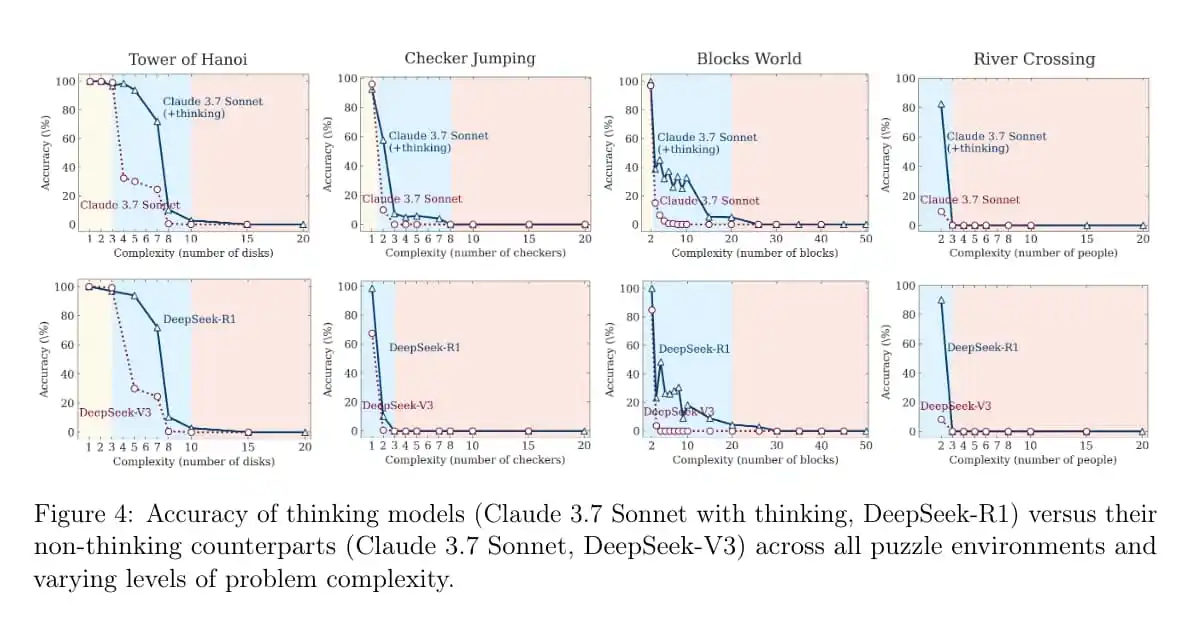
Apple tested advanced AI Large Reasoning Models (LRMs), using puzzles with adjustable difficulty and discovered that these models aren't truly reasoning in a general way.
The models fail completely when problems get too complex, use their "thinking" process inefficiently (sometimes "overthinking" easy problems), and can't even solve a puzzle correctly when given the exact step-by-step instructions.
This suggests their abilities are more about pattern matching from their training data than genuine, flexible problem-solving.
Paper: https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf